E4A正则表达式
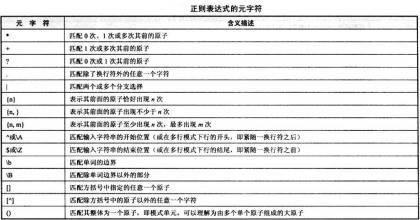
正则表达式,又称规则表达式。(英语:Regular Expression,在代码中常简写为regex、regexp或RE),计算机科学的一个概念。正则表达式通常被用来检索、替换那些符合某个模式(规则)的文本。
许多程序设计语言都支持利用正则表达式进行字符串操作。例如,在Perl中就内建了一个功能强大的正则表达式引擎。正则表达式这个概念最初是由Unix中的工具软件(例如sed和grep)普及开的。正则表达式通常缩写成“regex”,单数有regexp、regex,复数有regexps、regexes、regexen。
事件 按钮1.被单击()
变量 结果 为 文本型()
变量 个数 为 整数型
变量 计次 为 整数型
变量 内容 为 文本型
结果 = 正则匹配("adqwe中ds23e4文da321d","[\\u4e00-\\u9fa5]") '匹配文本中的中文字符
个数 = 取数组下标(结果,1)
如果 个数 > 0 则
变量循环首 计次 = 1 至 个数
内容 = 内容 & "\n" & 结果(计次 - 1)
变量循环尾
编辑框1.内容 = 内容
否则
编辑框1.内容 = "未找到匹配文本"
结束 如果
结束 事件 从上面的代码我们可以看出。正则表达式可以匹配一串字符串中的中文代码。并且以数组返回。而匹配的方法也非常的简单。就两个参数就可以完成中文字符串的匹配。这种功能经常被在我们要取出一些网页源码中特定的值。或者是取出类JSON的数据。
取中间文本
事件 按钮2.被单击()
变量 结果 为 文本型()
变量 个数 为 整数型
变量 计次 为 整数型
变量 内容 为 文本型
结果 = 取中间文本("这<是>一段<测试>文本","<",">")
个数 = 取数组下标(结果,1)
如果 个数 >= 1 则
变量循环首 计次 = 1 至 个数
内容 = 内容 & "\n" & 结果(计次 - 1)
变量循环尾
编辑框1.内容 = 内容
结束 如果
结束 事件 函数 取中间文本(待取文本 为 文本型,左边文本 为 文本型,右边文本 为 文本型) 为 文本型() 取中间文本 = 正则匹配(待取文本,"(?<=\\Q" & 左边文本 & "\\E).*?(?=\\Q" & 右边文本 & "\\E)") 结束 函数
上面的取中间文本其实和第一个自动全部匹配的效果都差不多,只不过在取中间的时候,我们可以进行批量的取出例如某个符号直之间的值。就像例程里面的取出<>中间的值。这种方法一般用于我们的进行批量取出中间文本的时候使用。
手动逐一匹配
事件 按钮3.被单击()
变量 内容 为 文本型
变量 位置 为 整数型
变量 结果 为 文本型
创建表达式("\\d",假,假) '\d表示匹配一个数字,由于\是E4A中的转义符号,所以要在前面再加一个\
开始匹配("a1bc2def3g")
判断循环首 匹配下一个() = 真
内容 = 取匹配文本() '取匹配到的文本
位置 = 取匹配开始位置() '取匹配到的文本在文本中的开始位置
结果 = 结果 & "\n" & "找到:" & 内容 & "---位置:" & 位置
判断循环尾
编辑框1.内容 = 结果
结束 事件 这一个正则匹配在我们平时用的比较多。首先我们需要先创建一个表达式。然后创建之后,紧接着开始匹配文本。那么这个时候系统会自动的开始使用上一步我们创建的表达式进行对文本的逐一匹配。当我们匹配下一个为真也就是说下一个匹配成功了。那么就返回匹配的结果。大家可以按照官方的例程自己手动练习一下。具体关于本正则详细课程,有专门的视频课程给大家讲解。大家可以在学习手册上面查找相应的视频课程进行学习。
全部替换
事件 按钮4.被单击()
变量 内容 为 文本型
创建表达式("\\d",假,假) '\d表示匹配一个数字,由于\是E4A中的转义符号,所以要在前面再加一个\
开始匹配("abc1de2fghi3jklm4n") '一定要先进行匹配
内容 = 全部替换("A") '将文本中的数字全部替换成字母A
编辑框1.内容 = 内容
结束 事件 全部替换的正则一般都是用于我们进行子问题批量正则替换的时候使用。
全部分割
事件 按钮5.被单击()
变量 分割 为 文本型()
变量 计次 为 整数型
变量 内容 为 文本型
创建表达式("\\d",假,假) '\d表示匹配一个数字,由于\是E4A中的转义符号,所以要在前面再加一个\
分割 = 全部分割("abc1de2fghi3jklm4n") '用匹配到的数字将这段文本进行分割
变量循环首 计次 = 0 至 取数组下标(分割,1)-1
内容 = 内容 & "\n" & 分割(计次)
变量循环尾
编辑框1.内容 = 内容
结束 事件 其实这段代码的意思很简单,就是用匹配的字符串去分割整个字符串。比如说。ASDF12HU4JUK这个字符串,先匹配数字,再用数字去分割这个字符串。
取子匹配文本
事件 按钮6.被单击()
变量 内容 为 文本型
变量 位置 为 整数型
变量 结果 为 文本型
变量 计次 为 整数型
创建表达式("[\\u4e00-\\u9fa5](\\d)",假,假) '匹配格式为:中文+(数字)
开始匹配("123你3好E4A易123安卓abc")
判断循环首 匹配下一个() = 真
内容 = 取匹配文本() '取匹配到的文本
位置 = 取匹配开始位置() '取匹配到的文本在文本中的开始位置
结果 = 结果 & "\n" & "找到:" & 内容 & "---位置:" & 位置
变量循环首 计次 = 1 至 取子匹配数量()
结果 = 结果 & "\n子匹配文本:" & 取子匹配文本(计次)
变量循环尾
判断循环尾
编辑框1.内容 = 结果
结束 事件 这段正则代码其实还是蛮重要的,在我们平时开发程序当中。尤其是将网页数据匹配到高级列表框中。用的非常常见,同时如果要自己使用PHP写API函数的话,也可以很方便的进行数据匹配。关于更多的使用方法请在视频课程中学习。
匹配网页链接
事件 按钮7.被单击()
变量 正则公式 为 文本型
'a href="http://detail.baidu.com/590266.html" title="男士洗面乳">
'a href="http:// 字母 .baidu.com/ 数字 .html" title=" 汉字 ">
正则公式="< a href=\"//(-+)../(0-9+)." title=\"400-95+">" '注意点号也是正则表达式里的符号,所以前面也要加上转义符
编辑框1.内容 = ""
创建表达式(正则公式,真,真)
开始匹配(读入资源文件("test.txt","GBK"))
判断循环首 匹配下一个()
编辑框1.内容 = 编辑框1.内容 & "\n" & 取匹配文本()
判断循环尾
结束 事件匹配网页链接其实原理都是差不多的,只不过这次使用的是正则公式。详细的正则公式大家可以去谷歌或者其他搜索引擎网站了解一下。
最后再说两句
正则表达式的使用,在我们开发程序的时候是非常重要的。大家如果不会正则的话,在以后的开发过程中,不管是自己开发还是接单开发,在数据处理的时候有的时候正则表达式可以帮助很大的忙,所以大家平时一定要注意。尽量把正则表达式学懂。

12121
不错,很全面。